OUR JOURNEY
The call, the crawl, and the counsels
Try it outIntroducingThe walk through
For 2022's JournalismAI Fellowship, Dataphyte Nigeria and Fædrelandsvennen from Norway bonded over the mission to develop an AI tool that can automatically create content from satellite, socioeconomic, weather, and web camera data to deliver customised content for local, regional and global audiences.
We tagged the project 'Nubia', based on the historical and anthropological significance of the name to Africa and the world. The name reflects the paradox about the vast size of Africa but the thousands of localities that are under-reported and sparsely contextualised, leading to many unknown and unreported grassroots economies, politics, and natural resources.
Country-level and international data on climate change, health, education, agriculture, and poverty is produced periodically across Africa. Yet, little data is reproduced as insights, analysis, or development news.
The call
The Fellowship project was born out of realisation that newsrooms with small teams are constrained from producing content from the enormous amount of data they curate or mine from various sources.
In many African countries, hundreds of socioeconomic datasets are frequently published by various sources but rarely turned into journalistic stories. Take, for example, revenue distribution data published by the Nigerian Bureau of Statistics (NBS). Journalists write at best five reports from the monthly dataset. At Dataphyte, we wish we could tell 800 stories based on the 800 distinct states and local governments highlighted in the dataset.
Taking the lead from our Norwegian colleagues' reality, we also saw a great opportunity to explore the use of web camera data, by building an AI tool that could spot irregular patterns or events on camera. For instance, the tool might spot car accidents or riots and alert journalists of a potential story to follow. Specific segments of the population- such as drivers, farmers, and security agencies - could leverage media insights from satellite and web cameras to make preventive decisions informed by data.
Altogether, we were driven by the goal of offering customised data and development reporting to specific audiences based on their location and interests. So we tasked the team to auto-generate news reports and data insights that can be distributed directly to the newsroom from satellite, socioeconomic, weather and web camera data.
The crawl, or what we learnt later - but not too late
As we began working on the project, we outlined our plan anchored on the primary goal to build a tool that would serve our editorial staff and target audiences with content based on real-time data. We planned to start with web cameras and satellite images. Next, we planned to do the same with weather data. The final step was to see how we could automate the aggregation and transformation of massive public data on socioeconomic indicators and development themes across cities, countries, and continents.
We started by designing a tool to parse datasets and store data as JSON files. From there, the data is managed and organised in a way that allows for the generation of articles that could be published more or less directly to the news site.
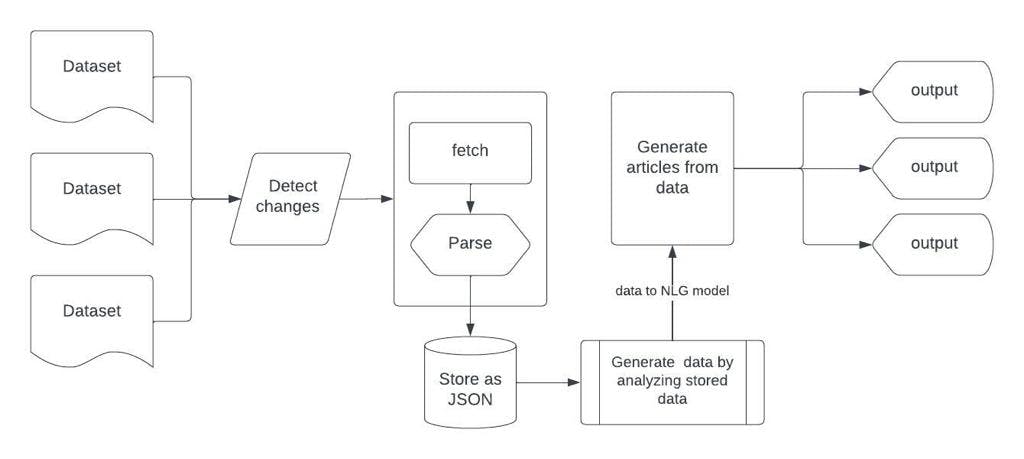
While we were hoping to build a model that aggregates data, parses it, and then generates insights all together, we realised that we might not have enough time to achieve all of the above during the Fellowship. After all, we were trying to perform three related-but-distinct operations at once: NLP, NLG, and Web alert.
We understood that for the duration of the Fellowship, we should narrow our goal to creating a tool that takes clean datasets and manually-written templates to generate articles based on multiple locations or named entities in the datasets.
At this rate, we realised we might only need an algorithm framework which can replace entry points pre-defined in a template with the value of an external dataset parsed to javascript objects to generate sentences. From there, we can proceed to return those generated articles as a response from API endpoints to whatever client side is receiving or calling them.
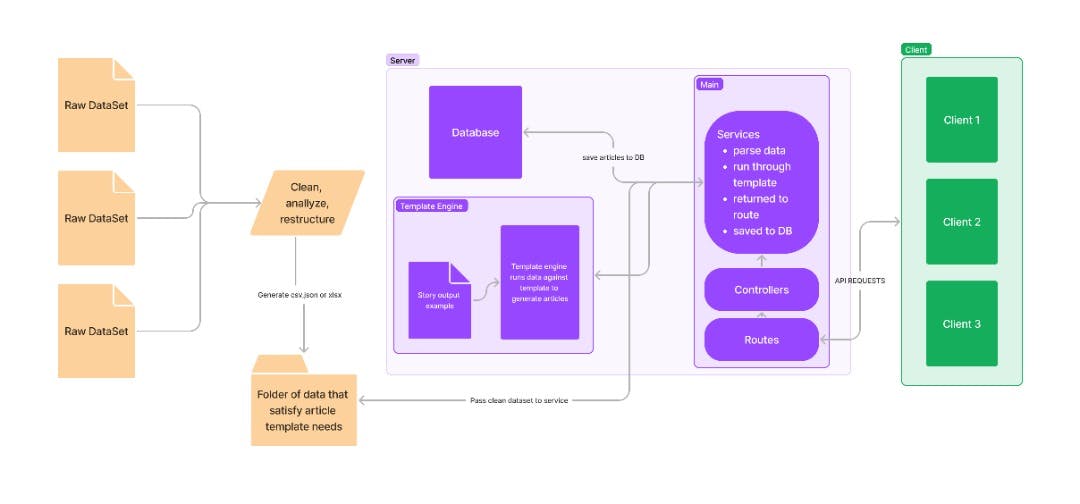
The MVP will require us to provide support to anyone who wants to generate stories via Nubia. In the future, we plan to add features that will allow users to upload their own datasets and design their template without support from the Nubia team.
Based on consultations, we realised our work could be simplified if we had access to OpenAI API, but the platform is currently inaccessible to our region, Africa.
The counsel: what we've learnt
We&aos;re still building out our idea, but we've already learned a few things worth sharing along the way. First lesson is to be clear about the aspect(s) of AI or machine learning that your project requires. Thanks to counsel from Gary Rogers, we were able to understand that the data types we initially thought to use had to be different from what we planned to use for our project.
We have also reviewed various listings, libraries, and frameworks dedicated to Natural Language Generation (NLG). One of our favourite posts, and the one we found most useful for building our MVP is RosaeNLG. Below you can find a list of other commercial and open-source tools we tested before settling on RosaeNLG.
Commercial tools for NLG:
Open-source tools and libraries:
- Core NLG
- Simplenlg
- Page detector
- Rosae NLG - Documentation & Github Repository